


Audio and acoustics

Video
Distant conversational speech recognition: Challenges and Opportunities
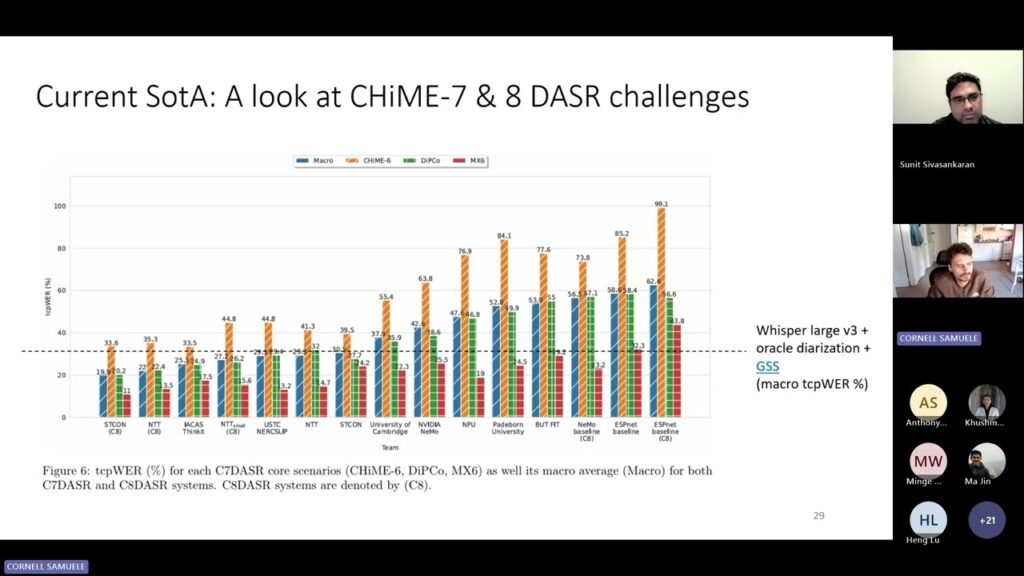
State-of-the-art ASR systems excel on close-talk benchmarks but struggle with far-field conversational speech, where error rates remain above 20%. Current benchmark datasets inadequately assess generalization across domains and real-world conditions, often relying on oracle segmentation…
Video
FOA Tokenizer: Learning Discrete Representations of Spatial Audio with Multichannel VQ-GAN
Spatial audio captures the directional and environmental characteristics of sound, enabling immersive listening experiences. First-Order Ambisonics (FOA) provides a compact representation of spatial audio by encoding the sound field’s directional components across four channels, allowing…

Video
Make some noise: Teaching the language of audio to an LLM using sound tokens
We investigate the use of low bitrate causal quantized audio representations to fine-tune large language models (LLMs) using LoRA for comprehending and generating audio. Differing from earlier approaches that depend on continuous audio representations for…

Video
Final intern talk: Distilling Self-Supervised-Learning-Based Speech Quality Assessment into Compact Models
In this talk, we explore advancements in computational models for speech quality assessment. Self-supervised learning models have emerged as powerful front-ends, outperforming supervised-only models. However, their large size renders them impractical for production tasks. We…
